
URL: https://msk.desy.de/e88987/e333178/e333869/index_ger.html
Breadcrumb Navigation
Reinforcement learning for beam tuning at ARES
Introduction
Tuning of particle accelerators is a notoriously difficult and time-consuming task. While some methods, such as numerical optimisers, have successfully been used to address these issues, many tuning tasks are too complex, high-dimensional and non-linear to be solved without more advanced methods. As a result, much of particle accelerators tuning can still only be done by hand by human experts with many years of experience. This manual tuning usually requires a lot of time, is difficult to reproduce and relies on the availability of the respective expert operators for each particular tuning task. Consequentially, the need for manual tuning reduces the research output particle accelerators are capable of delivering.
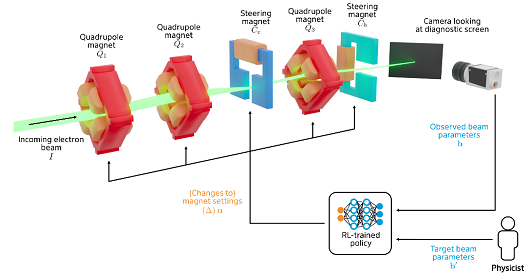
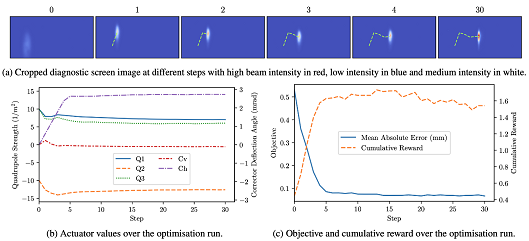
Reinforcement learning is an advanced machine learning method that has recently been shown to be capable of solving highly complex control problems like magnetic control of the plasma in a Tokamak fusion reactor. At ARES, we employ reinforcement learning in a so-called optimiser learning setup, to train a neural network to tune the transverse trajectory of the electron beam towards beam properties on a diagnostic screen as requested by the human operator. The fully trained agent manages to perform this tuning task about 4x faster than expert human operators, while achieving a tuning result as good as that achieved by the human operators. Notably, the trained agent never actually needed to interact with the real accelerator during training.
Instead, the agent has gathered experience equivalent to over 2 years of continuous beam time using a specially design high-speed simulation. Methods like domain randomisation ensure that the sim2real domain gap is then properly bridges without the requirement for fine-tuning on the real accelerator.
Ultimately, the experience gained and methods developed training this agent of the transverse beam tuning task at ARES can now be transferred to even more complex tasks on many other particle accelerators. The more of these autonomous tuning methods are deployed at these high-impact research facilities, the close we will get to a paradigm shift in accelerator operation, where physicists can focus on the requirements for their experiments instead of the settings required to achieve them, as the latter will one day be taken care of by autonomous accelerators.
Purpose/goal/objectives:
- Automation of complex particle accelerator tuning tasks that to-date can only be solved by expert operators because they cannot feasibly be solved by conventional methods such as numerical optimisation.
- Reduction of tuning times, ultimately increasing the availability of accelerators and their scientific output.
- Push the limits of operability to enable cutting edge experiments.
- Identification of methods for deploying reinforcement learning to complex real-world facilities.
References:
- J. Kaiser, C. Xu, A. Eichler, A. Santamaria Garcia, O. Stein, E. Bründermann, W. Kuropka, H. Dinter, F. Mayet, T. Vinatier, F. Burkart, H. Schlarb Learning to Do or Learning While Doing: Reinforcement Learning and Bayesian Optimisation for Online Continuous Tuning
arXiv, 2023 - C. Xu, J. Kaiser, E. Bründermann, A. Eichler, A.-S. Müller, A. Santamaria Garcia Beam Trajectory Control with Lattice-agnostic Reinforcement Learning Proceedings of the 14th International Particle Accelerator Conference, 2023.
- J. Kaiser, O. Stein, A. Eichler Learning-based Optimisation of Particle Accelerators Under Partial Observability Without Real-World Training Proceedings of the 39th International Conference on Machine Learning, 2022.
- A. Eichler, F. Burkart, J. Kaiser, W. Kuropka, O. Stein, E. Bründermann, A. Santamaria Garcia, C. Xu First Steps Toward an Autonomous Accelerator, A Common Project Between DESY and KIT Proceedings of the 12th International Particle Accelerator Conference, 2021.